Deep Learnig

El Deep Learning es una técnica de aprendizaje automático que enseña a los ordenadores a hacer lo que resulta natural para las personas: aprender mediante ejemplos. El Deep Learning es una tecnología clave presente en los vehículos sin conductor que les permite reconocer una señal de stop o distinguir entre un peatón y una farola. Resulta fundamental para el control mediante voz en dispositivos tales como teléfonos, tabletas, televisores y altavoces manos libres. El aprendizaje profundo atrae mucha atención últimamente, y hay razones de peso para ello. Está consiguiendo resultados que antes no eran posibles.
Con el Deep Learning, un modelo informático aprende a realizar tareas de clasificación directamente a partir de imágenes, texto o sonido. Los modelos de Deep Learning pueden obtener una precisión de vanguardia que, en ocasiones, supera el rendimiento humano. Los modelos se entrenan mediante un amplio conjunto de datos etiquetados y arquitecturas de redes neuronales que contienen muchas capas.
¿Como Funciona el Deep Learnig?
La mayor parte de los métodos de aprendizaje emplean arquitecturas de redes neuronales, por lo que, a menudo, los modelos de aprendizaje profundo se denominan redes neuronales profundas.
El término “profundo” suele hacer referencia al número de capas ocultas en la red neuronal. Las redes neuronales tradicionales solo contienen dos o tres capas ocultas, mientras que las redes profundas pueden tener hasta 150.
Los modelos de Deep Learning se entrenan mediante el uso de extensos conjuntos de datos etiquetados y arquitecturas de redes neuronales que aprenden directamente a partir de los datos, sin necesidad de una extracción manual de características.
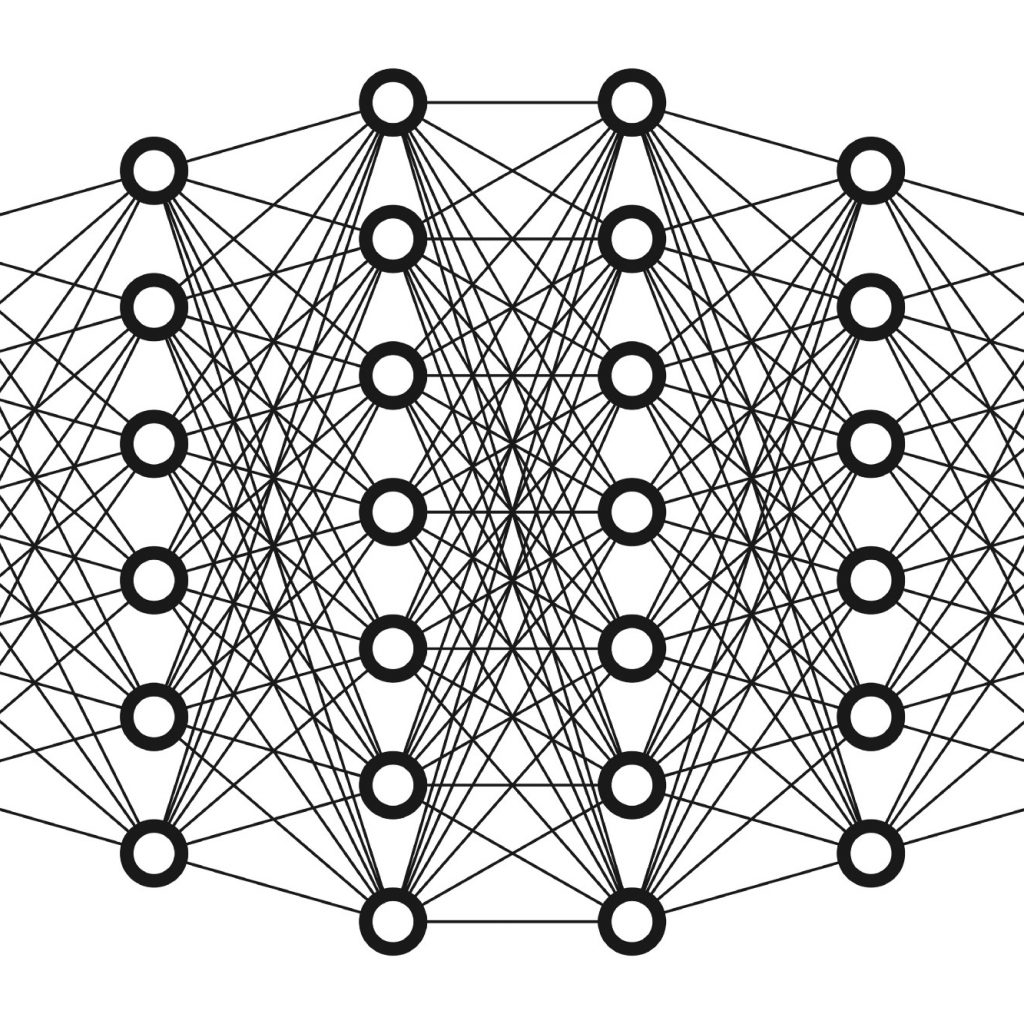
Uno de los tipos más populares de redes neuronales profundas son las conocidas como redes neuronales convolucionales (CNN o ConvNet). Una CNN convoluciona las características aprendidas con los datos de entrada y emplea capas convolucionales 2D, lo cual hace que esta arquitectura resulte adecuada para procesar datos 2D, tales como imágenes.
Las CNN eliminan la necesidad de una extracción de características manual, por lo que no es necesario identificar las características utilizadas para clasificar las imágenes. La CNN funciona mediante la extracción de características directamente de las imágenes. Las características relevantes no se entrenan previamente; se aprenden mientras la red se entrena con una colección de imágenes. Esta extracción de características automatizada hace que los modelos de Deep Learning sean muy precisos para tareas de visión artificial, tales como la clasificación de objetos.

